
Flink概述
1.Flink架构
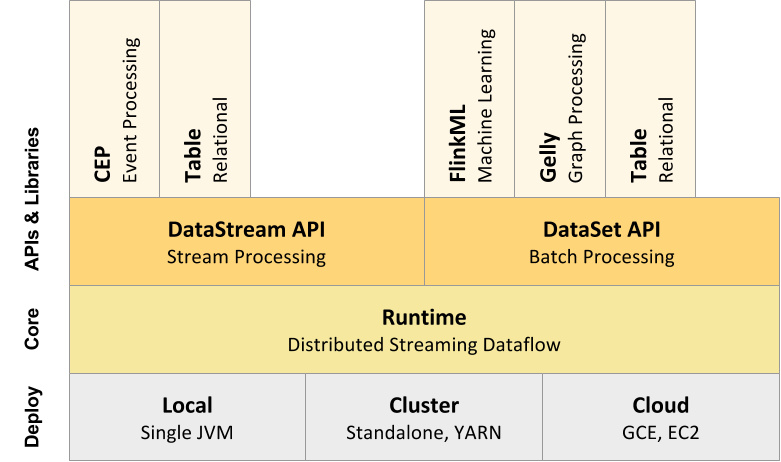
至下而上:
Deploy(部署):Flink 支持本地运行、能在独立集群或者在被 YARN 或 Mesos 管理的集群上运行, 也能部署在云上,即一共有三种部署模式:本地部署、Yarn模式、远程模式。
- Runtim(运行):Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
- API:DataStream、DataSet、Table、SQL API。
- 拓展库:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
2.Flink组件
Flink工作原理
Job Managers、Task Managers、客户端(Clients)
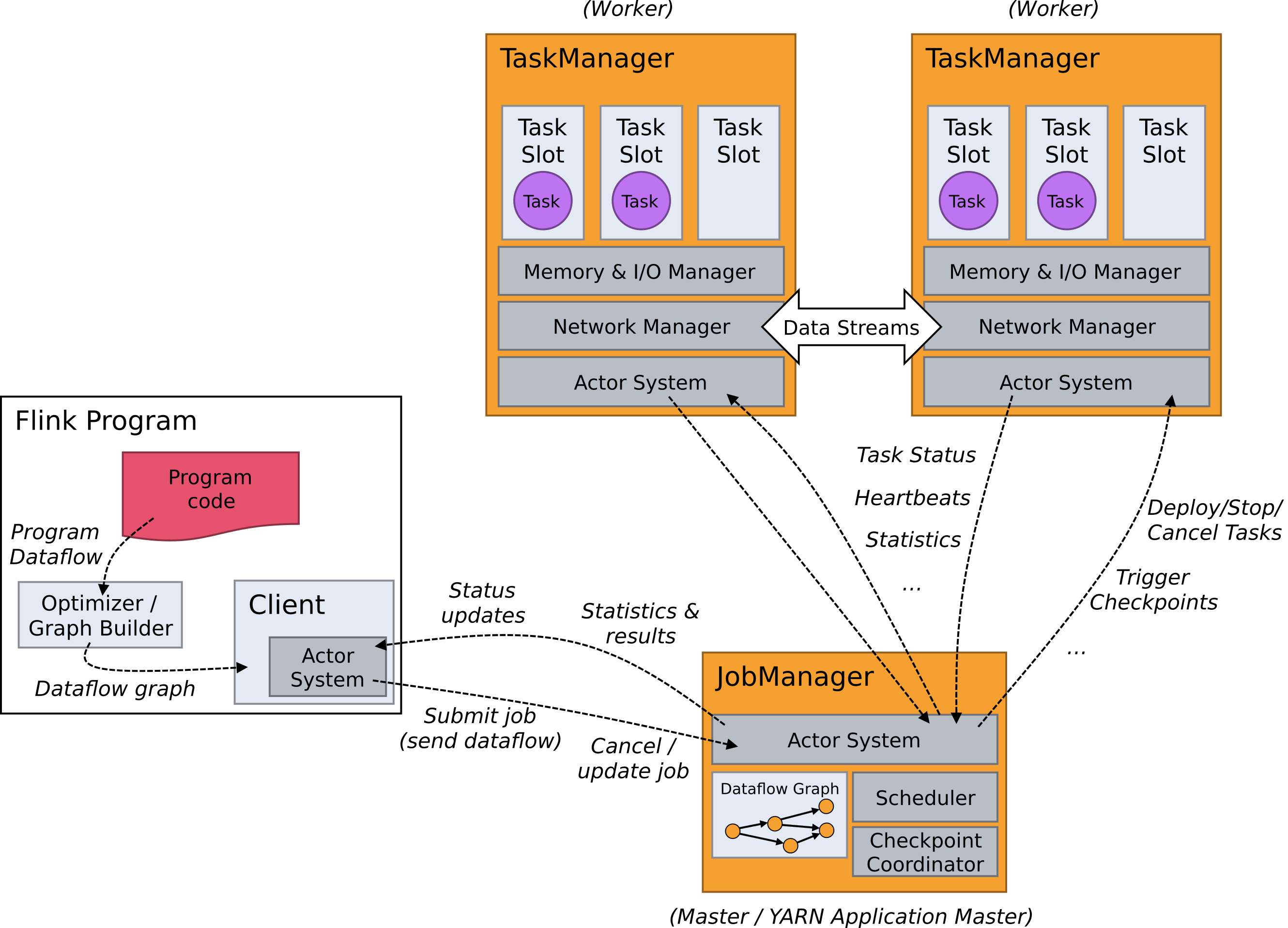
Flink程序需要提交给Client。 然后,Client将作业提交给Job Manager。 Job Manager负责协调资源分配和作业执行。 它首先要做的是分配所需的资源。 资源分配完成后,任务将提交给相应的Task Manager。 在接收任务时,Task Manager启动一个线程以开始执行。 执行到位时,Task Manager会继续向Job Manager报告状态更改。 可以有各种状态,例如开始执行,正在进行或已完成。 作业执行完成后,结果将发送回Client。
Flink 运行时包含两类进程:
- JobManagers (也称为 masters)协调分布式计算。它们负责调度任务、协调 checkpoints、协调故障恢复等。每个 Job 至少会有一个 JobManager。高可用部署下会有多个 JobManagers,其中一个作为 leader,其余处于 standby 状态。这个进程由三个不同的组件组成:
- ResourceManager ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
- TaskManagers(也称为 workers)执行 dataflow 中的 tasks(准确来说是 subtasks ),并且缓存和交换数据 streams。每个 Job 至少会有一个 TaskManager。
JobManagers 和 TaskManagers 有多种启动方式:直接在机器上启动(该集群称为 standalone cluster),在容器或资源管理框架,如 YARN 或 Mesos,中启动。TaskManagers 连接到 JobManagers,通知后者自己可用,然后开始接手被分配的工作。
客户端(Client)虽然不是运行时(runtime)和作业执行时的一部分,但它是被用作准备和提交 dataflow 到 JobManager 的。提交完成之后,客户端可以断开连接,也可以保持连接来接收进度报告。客户端既可以作为触发执行的 Java / Scala 程序的一部分,也可以在命令行进程中运行./bin/flink run ...。
Task Slots 的隔离&共享
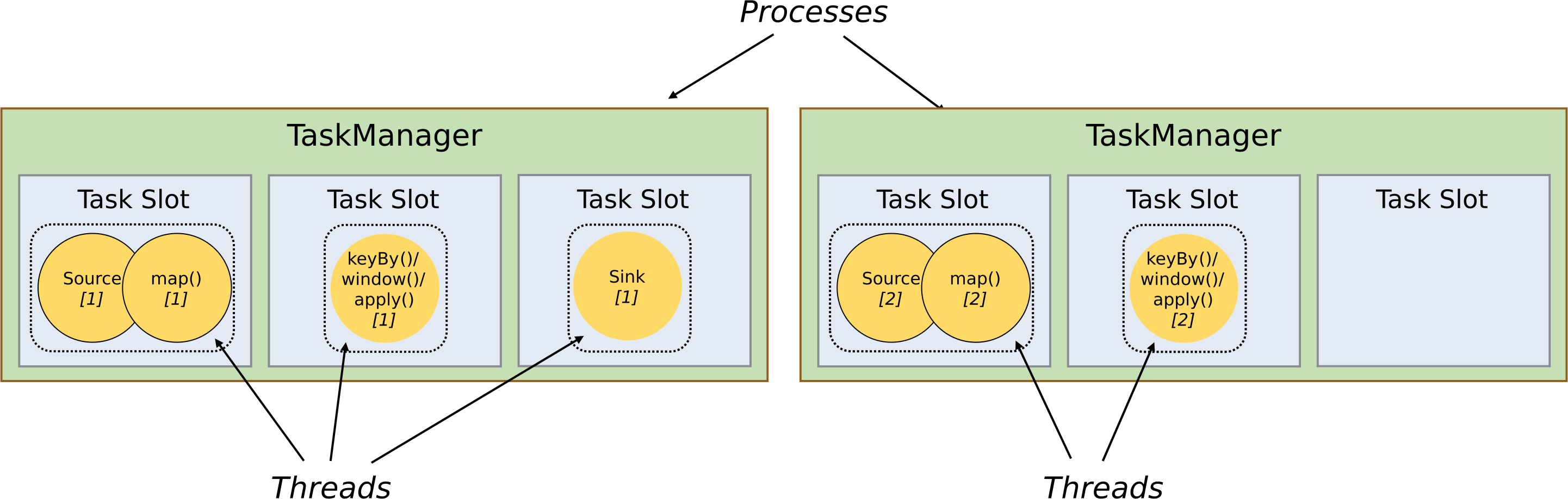
TaskManager并不是最细粒度的概念,每个TaskManager像一个容器一样,包含一个多或多个Slot。
Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManger的内存,比如TaskManager分配给Solt的内存为8G,两个Slot,每个Slot的内存为4G,四个Slot,每个Slot的内存为2G,值得注意的是,Slot仅划分内存,不涉及cpu的划分。同时Slot是Flink中的任务执行器,每个Slot可以运行多个task,而且一个task会以单独的线程来运行。Slot主要的好处有以下几点:
- 可以起到隔离内存的作用,防止多个不同job的task竞争内存。
- Slot的个数就代表了一个Flink程序的最高并行度,简化了性能调优的过程
- 允许多个Task共享Slot,提升了资源利用率
默认情况下,Flink 允许 subtasks 共享 slots,即使它们是不同 tasks 的 subtasks,只要它们来自同一个 job。因此,一个 slot 可能会负责这个 job 的整个管道(pipeline)。允许 slot sharing 有两个好处:
- Flink 集群需要与 job 中使用的最高并行度一样多的 slots。这样不需要计算作业总共包含多少个 tasks(具有不同并行度)。
- 更好的资源利用率。在没有 slot sharing 的情况下,简单的 subtasks(source/map())将会占用和复杂的 subtasks (window)一样多的资源。通过 slot sharing,将示例中的并行度从 2 增加到 6 可以充分利用 slot 的资源,同时确保繁重的 subtask 在 TaskManagers 之间公平地获取资源。
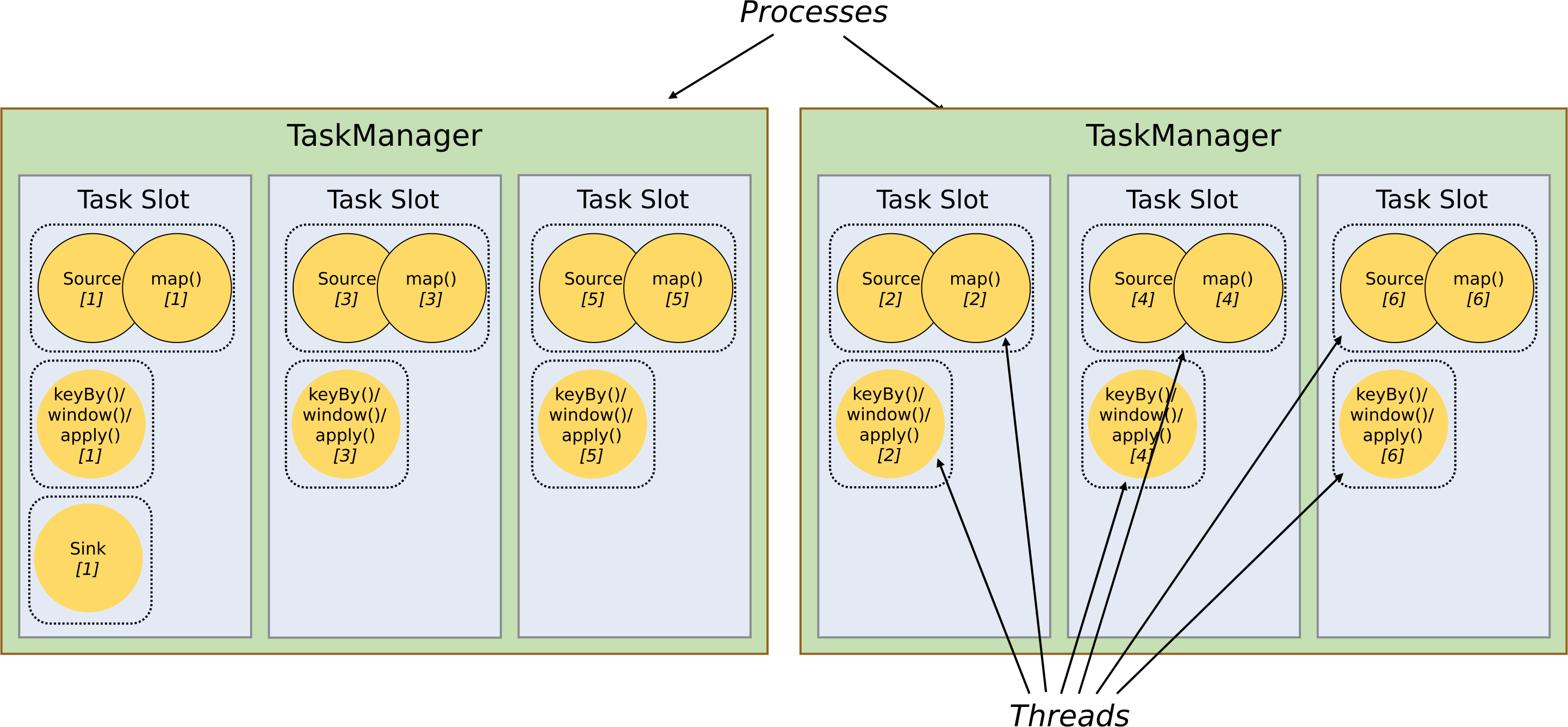
Flink 内部通过 SlotSharingGroup 和 CoLocationGroup 来定义哪些 task 可以共享一个 slot, 哪些 task 必须严格放到同一个 slot。
根据经验,合理的 slots 数量应该和 CPU 核数相同。在使用超线程(hyper-threading)时,每个 slot 将会占用 2 个或更多的硬件线程上下文(hardware thread contexts)。
参考