
1. Join原理
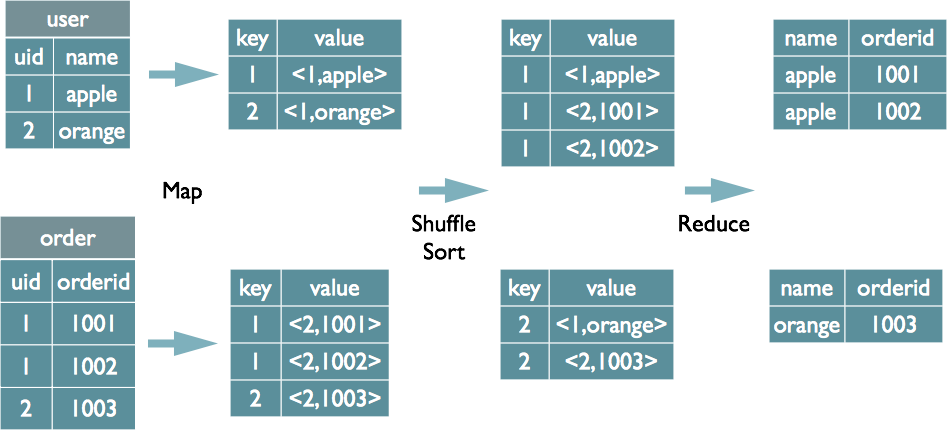
有两个表User、Order如上,进行Join操作
1 2 3 4 5
SELECT u.name, o.orderid FROM user u JOIN order o ON u.uid = o.uid;
Hive会将On之后的条件作为Key,将Select的字段作为Value,构建(Key,Value),同时为每张表打上Tag标记用来标记自己是哪站表。
在Shuffle阶段按Key分组
在Reduce阶段进行数据整合
2. 各种Join操作
2.1 Inner Join(内连接)
1
2
3
4
5
SELECT
u.name,
o.orderid
FROM my_user u
[INNER] JOIN my_order o ON u.uid = o.uid;
2.2 Left Outer Join(左外连接)
1
2
3
4
5
SELECT
u.name,
o.orderid
FROM my_user u
LEFT OUTER JOIN my_order o ON u.uid = o.uid;
2.3 Right Outer Join(右外连接)
1
2
3
4
5
SELECT
u.name,
o.orderid
FROM my_user u
RIGHT OUTER JOIN my_order o ON u.uid = o.uid;
2.4 Full Outer Join(全外连接)
1
2
3
4
5
SELECT
u.name,
o.orderid
FROM my_user u
FULL OUTER JOIN my_order o ON u.uid = o.uid;
2.5 Left Smei Join(左半开连接)
只能Select昨天表的内容,也只会输出左边表的内容
1
2
3
4
SELECT
*
FROM my_user u
LEFT SEMI JOIN my_order o ON u.uid = o.uid;
3. Join优化
在正常生产环境下,上述Join操作虽然通用,但是会很浪费时间,因为不仅需要Map阶段,还需要Reduce阶段整合数据,所以上述Join操作也称作(Reduce Side Join)
3.1 Map Side Join
省略Reduce端,直接在Map端进行整合数据
也就是将其中一张表分别放入每个Map端,这样就可以在Map端将两张表进行整合,但前提是能分别放入每个Map端的那张表必须足够小

上面就是Map Side Join的原理了,可以看出每个Mapper里面都会有一个Small Table Data,这样就可以在Map端完成两张表的Join
- 默认情况下,25M一下的算小表,该属性由
hive.smalltable.filesize决定。
1
2
3
4
5
6
7
8
9
10
11
-- 使用方式一:
-- 使用 /*+ MAPJOIN(tbl)*/ tbl为表名
SELECT
/*+ MAPJOIN(my_order)*/
u.name,
o.orderid
FROM my_user u
LEFT OUTER JOIN my_order o ON u.uid = o.uid;
-- 方式二:设置hive.auto.convert.join = true,这样hive会自动判断当前的join操作是否合适做map join,主要是找join的两个表中有没有小表。
3.2 Bucket Map Join
但是当两张表都不是小表改怎么时,就需要使用Bucket Map Join
Bucket Map Join 使用需求
- 两张表的连接字段必须为分桶字段
- 两张表的分桶数量必须相同或是倍数关系
- 设置属性
hive.optimize.bucketmapjoin= true控制hive 执行bucket map join- Map端接受N个小表的Hashtable,做连接操作时,只需要Hashtable放入内存,然后将大表对应的Hashtable进行连接,所以内存限制为最大的那张Hashtable
3.2 Sort Merge Bucket Map Join
如果对于Bucket Map Join中的两张分桶表是有序的,是可以进行Sort Merge Bucket Map Join
由于两张表是有序的,那么在两张表每个桶局部连接时,只需要将每张表便利一次便可以完成整合操作,甚至不用把一个Bucket完整的加载成Hashtable
使用设置
1
2
3
set hive.optimize.bucketmapjoin= true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;