
Hive概念以及架构
0. 目录
- 什么是Hive
- Hive 体系介绍
- Hive 执行任务的流程
1. 什么是Hive
- Hive是Hadoop工具家族中一个重要成员,可以将结构化的数据文件(HDFS)映射为一张数据库表。
- Hive 定义了简单的类 SQL 查询语言,被称为 HQL,实现方便高效的数据查询
- Hive的本质是将HQL,转换成MapReduce任务,完成整个的数据的ETL,减少编写MapReduce的复杂度
2.Hive体系介绍
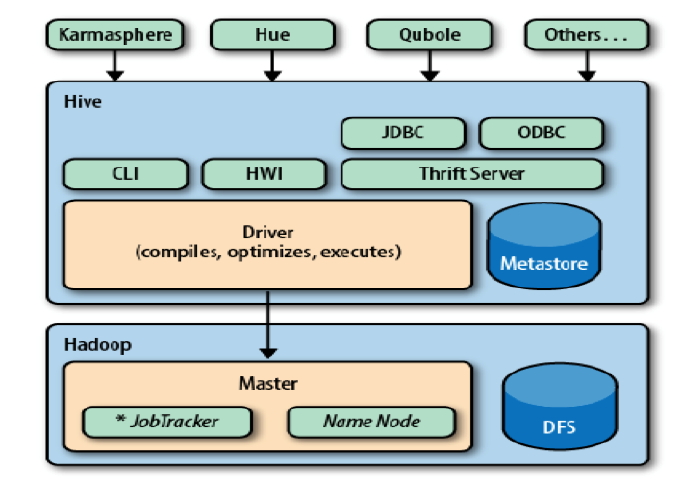
Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、Hive WEB Interface(HWI)、Metastore和Driver(Complier、Optimizer和Executor)
- Driver:核心组件。整个Hive的核心,该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
- Metastore: 元数据服务组件。这个组件存储Hive元数据,放在关系型数据库中,支持derby、mysql。
- ThriftServers:提供JDBC和ODBC接入的能力,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
- CLI:command line interface,命令行接口
- Hive WEB Interface(HWI):hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface)
3. Hive执行流程
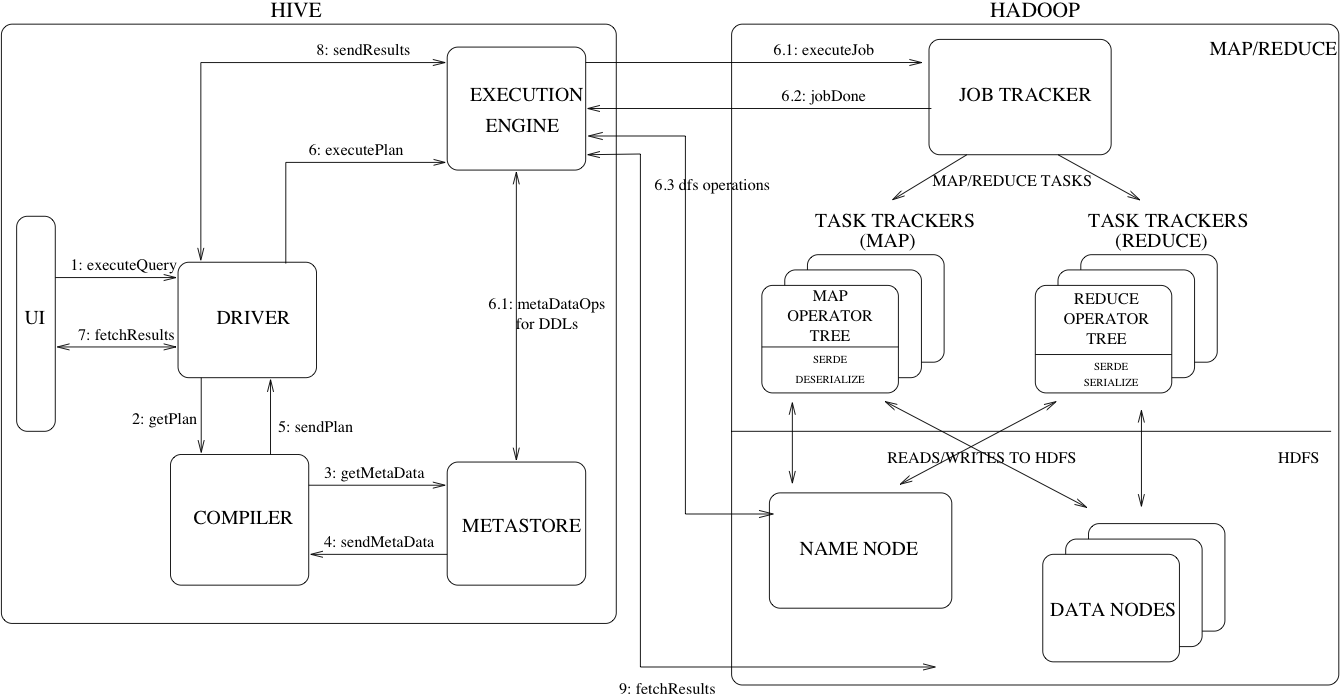
- UI调用Drive的execute接口(1)
- Drive创建一个查询的Session事件并发送这个查询到Compiler,Compiler收到Session生成执行计划(2)
- Compiler从MetaStore中获取一些必要的数据(3,4)
- 在整个Plan Tree中,MetaStore用于查询表达式的类型检查,以及根据查询谓语(query predicates)精简partitions 。该Plan由Compiler生成,是一个DAG(Directed acyclic graph,有向无环图)执行步骤,里面的步骤包括
map/reduce job、metadata操作、HDFS上的操作,对于map/reduce job,里面包含map operator trees和一个reduce operator tree(5) - 提交执行计划到
Excution Engine,并由Execution Engine将各个阶段提交个适当的组件执行(6,6.1,6.2 , 6.3) - 在每个任务(mapper / reducer)中,表或者中间输出相关的反序列化器从HDFS读取行,并通过相关的操作树进行传递。一旦这些输出产生,将通过序列化器生成零时的的HDFS文件(这个只发生在只有Map没有reduce的情况),生成的HDFS零时文件用于执行计划后续的Map/Reduce阶段。对于DML操作,零时文件最终移动到表的位置。该方案确保不出现脏数据读取(文件重命名是HDFS中的原子操作),对于查询,临时文件的内容由Execution Engine直接从HDFS读取,作为从Driver Fetch API的一部分(7,8,9)