
Impala 简介
- 基于Google的Dremel 为原型的查询引擎,Cloudera公司推出,提供对HDFS、HBase数据的高性能、低延迟的交互式SQL查询功能
- Impala是一个分布式、大规模并行处理(MPP)的服务引擎
- 使用内存进行Hive,兼顾数据仓库、实时、批处理、多并发等优点
Impala各进程角色
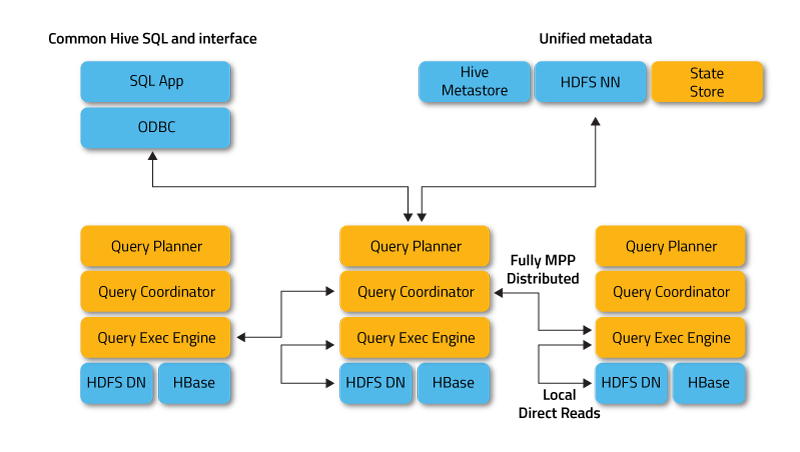
- State Store Daemon
- 负责收集分布在各个ImpalaD进程的资源信息、各节点健康状况,同步节点信息
- 负责调度Query
- Catalog Daemon
- 主要跟踪各个节点上对元数据的变更操作,并且通知到每个ImpalaD。
- 接受来自StateStore的所有请求
- Impala Daemon
- Query Planner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询
- Query Coordinator将这些子查询分发到各个节点上
- 各个节点上的Query Exec Engine负责子查询的执行,然后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
Impala查询数据流程
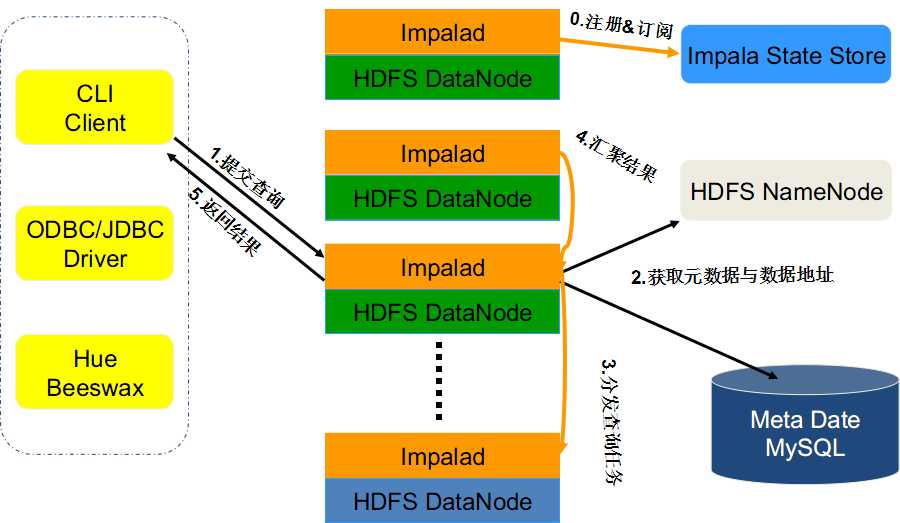
注册&订阅:当Impala启动时,所有Impalad节点会在Impala State Store中注册并订阅各个节点最新的健康信息以及负载情况。
- 提交查询:接受此次查询的ImpalaD作为此次的Coordinator,对查询的SQL语句进行分析,生成并执行任务树,不同的操作对应不同的PlanNode,如:SelectNode、 ScanNode、 SortNode、AggregationNode、HashJoinNode等等。
- 获取元数据与数据地址:Coordinator通过查询数据库,或者HDFS文件获取到此次查询的数据库所在的具体位置,以及存储方式的信息
- 分发查询任务:执行计划树里的每个原子操作由Plan Fragment组成,通常一句SQL由多个Fragment组成。Coordinator节点根据执行计划以及获取到的数据存储信息,通过调度器将Plan Fragment分发给各个Impalad实例并行执行。
- 汇聚结果:Coordinator节点会不断向各个Impalad执行子节点获取计算结果,直到所有执行计划树的叶子节点执行完毕,并向父节点返回计算结果集。
- Coordinator节点即执行计划数的根节点,汇聚所有查询结果后返回给用户。查询执行结束,注销此次查询服务。
Impala优缺点
优点:
- Impala直接在内存进行计算不需要把中间结果写入磁盘,省掉了大量的I/O开销;
- 支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销;
- Impala直接通过应用的服务进程来进行任务调度,省掉了MR作业启动的开销
- 使用C++实现,并做了硬件优化
缺点:
- 对内存需求过高,没有内存溢出写入外存的机制;
- 不支持数据的UPDATE/DELETE,对配置类数据的处理不好;
- 对数据挖掘类的操作处理还不够丰富,但已能满足日常大部分的统计分析需求。
Impala Join操作
Broadcast Join
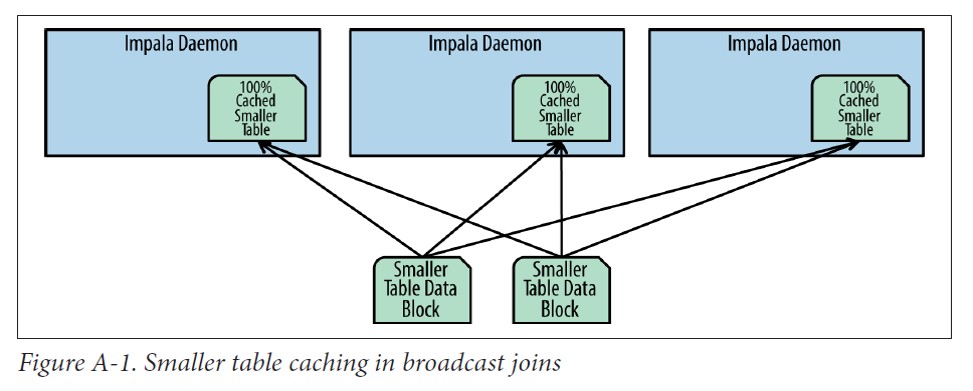
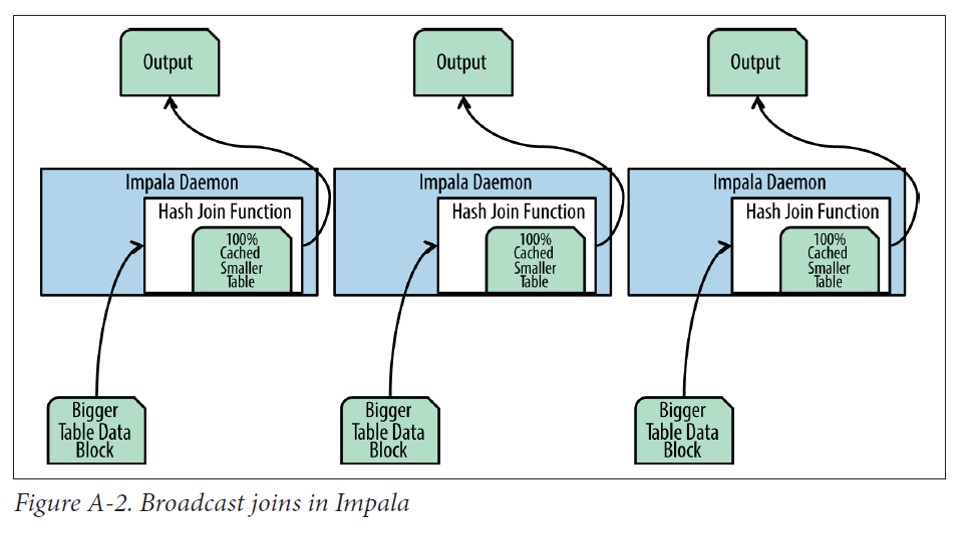
- Impala将较小的表通过网络分发到执行任务的Impala后台进程中
- 小表数据分发并缓存完成后,大表的数据就流式地通过内存中小表的哈希表。每个Impala进程负责大表的一部分数据,扫面读入,并用哈希连接的函数计算值。
- 大表的数据一般由Impala进程从本地磁盘读入从而减少网络开销。由于小表的数据已经缓存在每个节点中,因此在此阶段唯一可能的网络传输就是将结果发送给查询计划中的另一个连接节点。
Partitioned Hash Join
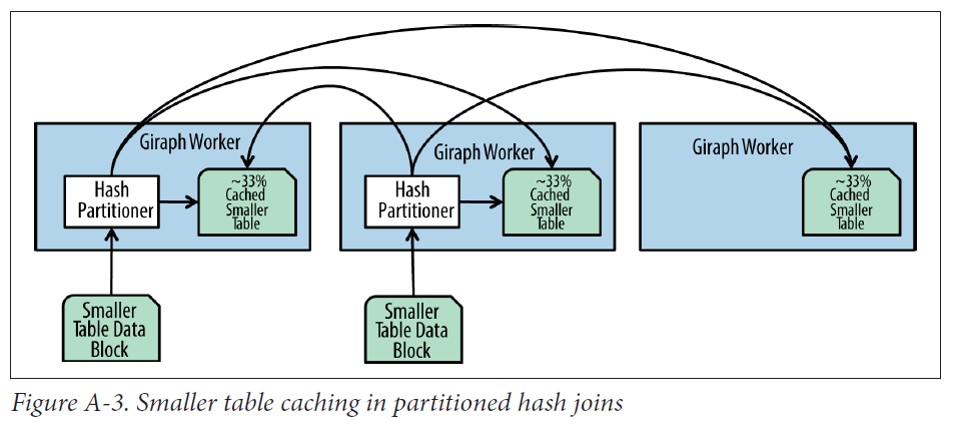
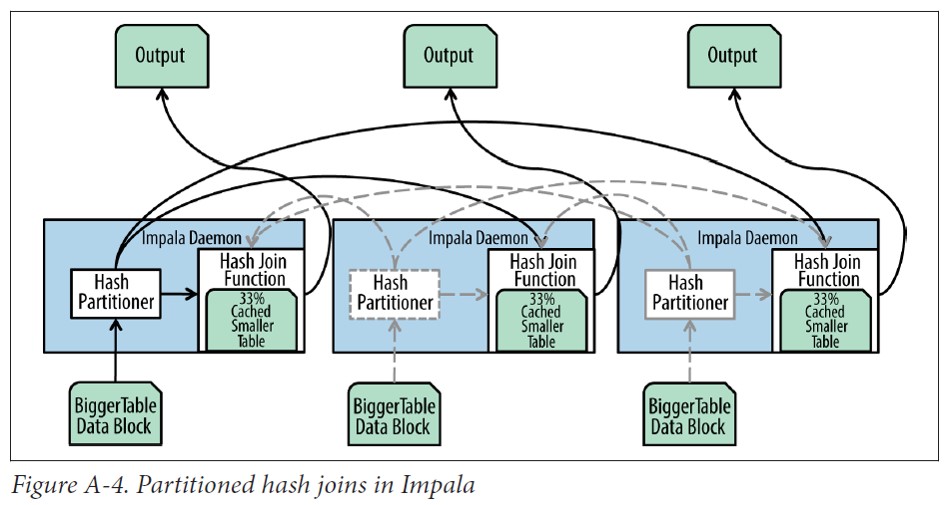
分区哈希连接需要更多的网络开销,但可以允许大表的连接而不要求整个表的数据都能放到一个节点的内存中。当统计数据显示表太大而无法放到一个节点的内存中或者有查询提示时就会使用分区哈希连接。
进行分区哈希连接时(也称为shuffle join),每个Impala进程读取两个表的本地数据,使用一个哈希函数进行分区并把每个分区分发到不同的Impala进程。
正如上图所示,大表的数据也通过相同的哈希函数就行分区并把分区发送能和小表相应数据进行连接的结点。注意,和广播连接不同的是,广播连接只有小表的数据需要通过网络分发,而分区哈希连接需要通过网络分发大表和小表的数据,因此需要更高的网络开销。
Impala有两种连接策略:广播连接,需要更多的内存并只适用于大小表连接。分区连接,需要更多的网络资源,性能比较低,但是能进行大表之间的连接。
Impala中的资源管理
- 静态资源池
- CDH中将各服务彼此隔开,分配专用的资源
- 动态资源池
- 用于配置及用于在池中运行的yarn或impala查询之间安排资源的策略
Impala2.3之前使用的是yarn作为资源调度,2.3之后自身的资源调度策略Long-Lived Application Master,即LIAMA
Impala使用
- 查看当前语句所需资源
1
2
explain [sql语句]
explain select count(*) from action;
- 设置资源池名称
1
set request_pool = impala100;
- 设置最大内存使用限制
1
set mem_limit=100m
- 设置执行计划显示信息详细程度,等级越高越详细
1
set explain_level=3;
- 同步HIVE所有的数据库信息到Impala
1
INVALIDATE METADATA;
- 同步某张表信息
1
REFRESH [table_name]
Impala优化(待补充)
- 维度建模
- 维度表
- 事实表
- 星型模型
- 雪花模型
- 文件存储格式
- Parquet
- Text
- Avro
- Rcfile
- SQL Tuning
- Explain
- Join
- 数据裁剪