
Spark入门
1.什么是Sark
Apache Spark是一个开源集群运算框架。
相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。
Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。
2. Spark部件
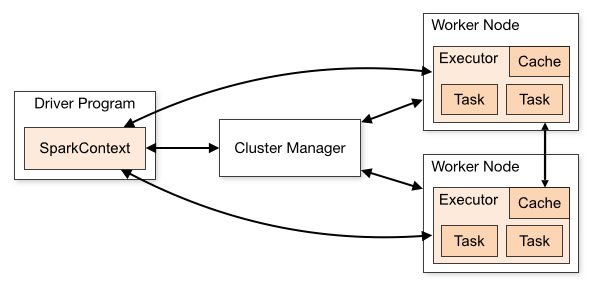
Driver Program:一个独立的进程,主要是做一些job的初始化工作,包括job的解析,DAG的构建和划分并提交和监控taskCluster Manager:一个进程,用于负责整个集群的资源调度、分配、监控等职责Work Node:负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令Executor:启动多个Task执行RDD操作,Task用于执行RDD操作Cache:用于缓存数据
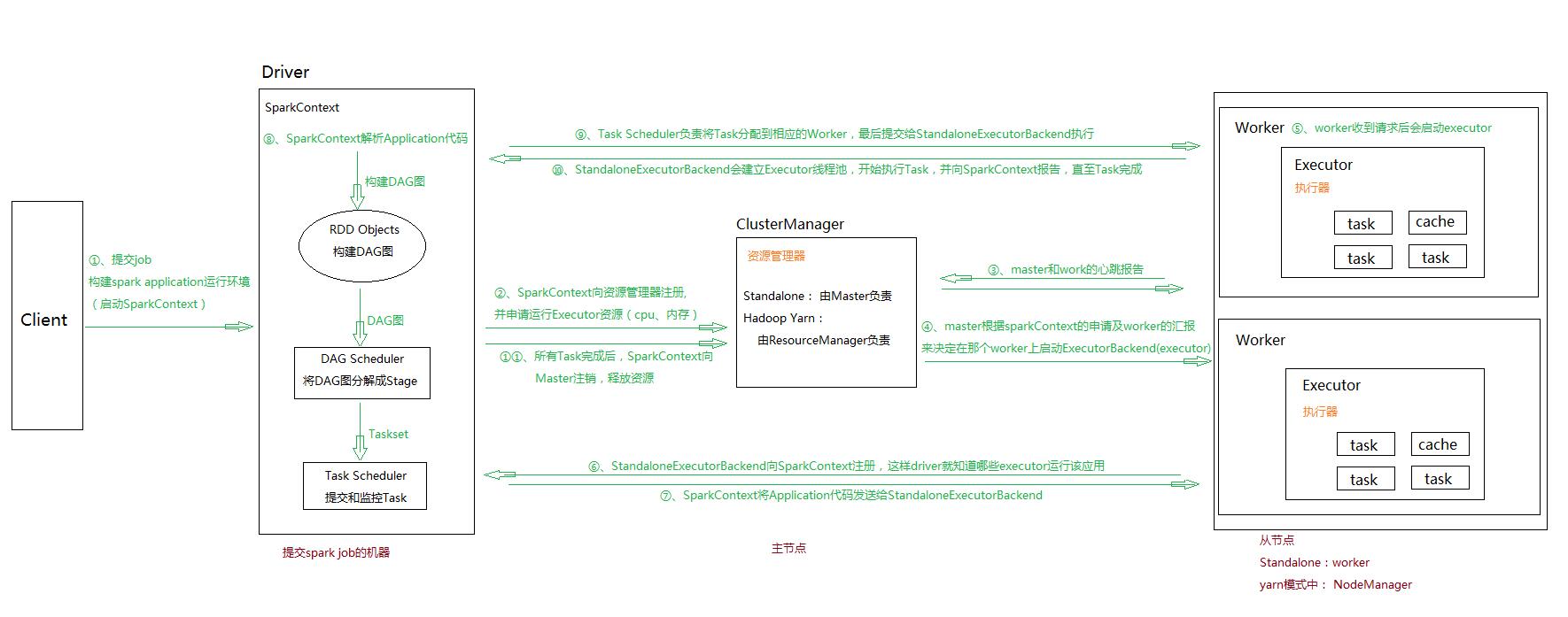
具体流程:
3. RDD&&RDD操作
3.1 什么是RDD
弹性分布式数据集(Resilient Distributed Datasets ,RDDs)是一个可以并行操作的容错元素集合,由多个Partition组成

3.2 RDD怎么创建
RDD一共有两个创建方式:
- 并行化(parallelize)一个程序中现有的集合
- 引用一个外部数据集(HDFS, HBase, or any data source offering a Hadoop InputFormat)
1
2
3
4
5
6
7
//并行化一个现有集合
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
//从HDFS文件中读取一个文件
val sc = new SparkContext(conf)
val f = sc.textFile("hdfs://root/user")
f: RDD[String] = MappedRDD@1d4cee08
3.3 RDD常用操作
Transformation:进行数据的转换,即将一个RDD转换成另一个RDD,这类转换并不触发提交作业,完成作业中间过程处理。
- map:将集合中的每个对象进行遍历操作,传入的匿名函数即为遍历的每个元素的操作
- filter:传入你个返回为Boolean的匿名函数,返回 返回值为True的对象
- flatMap:将处理返回的迭代类容构建成一个新的RDD
1
2
3
4
5
6
7
list=["im am a good man","you are a bad girl"]
parallelize = sc.parallelize(list)
flat_map = parallelize.flatMap(lambda x: x.split(" "))
# 输出结果 ['im', 'am', 'a', 'good', 'man', 'you', 'are', 'a', 'bad', 'girl']
# 与map不同的地方在与,map输出结果
# [['im', 'am', 'a', 'good', 'man'],['you', 'are', 'a', 'bad', 'girl']]
- groupByKey:传入的必须是一个键值对(长度为2就完事了),根据键进行分组 注意:在实际使用的时候能使用reduceByKey或者aggregateByKey就用这两个,可以有效减少shuffle
1
2
3
list=[("m",10),("m",20),("c",18)]
listRDD=sc.parallelize(list).groupByKey()
# listRDD:[('m', (10,20), ('c', (18))]
- reduceByKey:groupByKey+reduce,对传入的键值对进行分组并进行reduce计算
- sortByKey:根据键值对的Key进行排序
- join:跟SQL中的Join差不多
- cogroup:跟join差不多,不过join后返回的是一个可以迭代的对象
- union:将两个RDD合并,不去重
- intersection:取两个RDD交集,并去重
- distinct:去重
- aggregateByKey:有点麻烦 参考 aggregateByKey
Action:计算,对RDD数据进行计算,会触发SparkContext提交Job作业。
reduce:通过传入的func函数聚集RDD中所有的元素
1 2 3 4
val arr=Array(1,2,3,4,5,6) val value = sc.parallelize(arr) val i = value.reduce(_+_)
collect:以数组的形式返回所有的元素
count:返回RDD的个数
first:返回RDD的第一个元素
take:取出RDD前N个元素,以数组的形式返回
saveAsTextFile:将RDD保存为一个文件
countByKey:分组计数
参考