DAGScheduler实现
1.DAGScheduler的创建
TaskScheduler和DAGScheduler都是在SparkContext创建的时候创建的。其中TaskScheduler是通过org.apache.spark.SparkContext#createTaskScheduler创建的,而DAGScheduler是直接调用构造函数创建的。只不过DAGScheduler中保存了TaskScheduler的引用,因此需要在TaskScheduler创建之后创建
SparkContext
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 在SparkContext中创建DAGScheduler
_dagScheduler = new DAGScheduler(this)
// 构造函数的实现
def this(sc: SparkContext) = this(sc, sc.taskScheduler)
// 继续跟进
def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
}
//里面的this
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
...
}
2. Job的提交
用户提交的Job最终会执行DAGScheduler的runjob,以foreach为例,过程如下
org.apache.spark.rdd.RDD#foreach
org.apache.spark.SparkContext#runJob
org.apache.spark.scheduler.DAGScheduler#runJob
org.apache.spark.scheduler.DAGScheduler#submitJob
org.apache.spark.scheduler.DAGSchedulerEventProcessLoop#doOnReceive(case JobSubmitted)
org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
简单描述一下,foreach会触发SparkContext中的runjob,SparkContex中的runjob会不断调用SparkContext中的其他重载的runjob,最终会调用DAGScheduler中的runjob
runjob
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 调用submitJob来处理
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// 接受处理完成后的状态
waiter.awaitResult() match {
case JobSucceeded =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case JobFailed(exception: Exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
submitJob
1
2
3
4
5
6
7
8
9
10
// 首先会生成JobID
val jobId = nextJobId.getAndIncrement()
...
// 然后创建一个waiter用来监控Job的执行状态
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// 最后向eventProcessLoop提交Job
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
最终eventProcessLoop接收到JobSubmitted,然后调用handleJobSubmitted处理Job
1
2
3
4
5
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
...
}
3. Stage的划分
3.1 什么是Stage
用户提交的计算任务是由一个RDD构成的DAG,如果DAG在转换的时候需要做Shuffle,那么Shuffle的过程就给这个DAG分成了不同的Stage。其中不同的Stage不同并行计算,因为需要计算的数据来源于上一个Stage,而同一个Stage由一组完全独立的Task组成,每个Task计算逻辑完全相同,但是所处理的数据不同,这些数据也就是Partition,所以Task的数量是与Partition一一对应的
具体Shuffle的流程以及宽依赖窄依赖可以看另一篇博文:Spark内部原理
3.2 划分流程
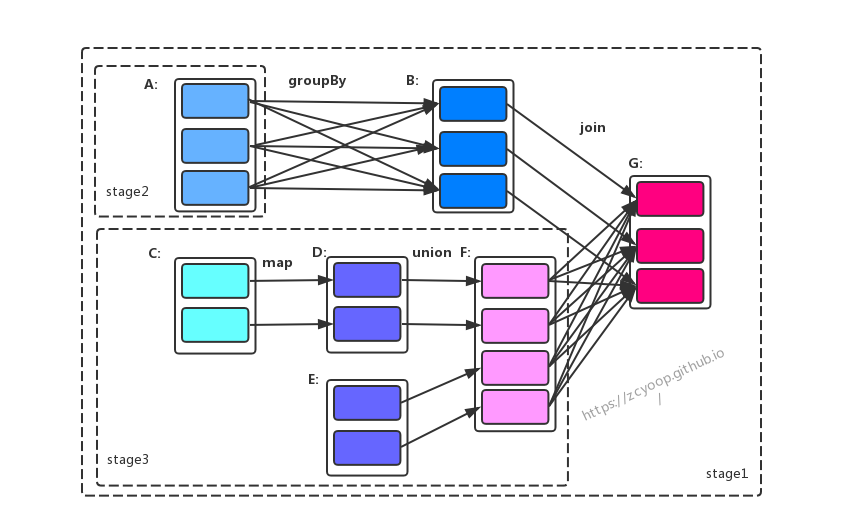
简述一下划分过程:
- 首先Stage会从最后一个开始划分,也就是触发Action的那个,也就是图中的 RDD G
- RDD G 依赖 RDD B、RDD F,会随机选择一个进行处理,这里我以RDD B 开始
- 由于RDD G 和 RDD B之间为窄依赖,所以RDD B 会和 RDD G 划分在同一个Stage (Stage 3)
- RDD F 和 RDD G 之间为宽依赖 ,则 RDD F 和 RDD G 被划分到不同的Stage (Stage3、Stage2),其中Stage3 的parentRDD 就是Stage2
- 继续处理RDD B ,由于RDD B与RDD A为宽依赖,所以被划分到不同的Stage(Stage3、Stage1)
- RDD F 同理,与其他几个RDD 均为窄依赖,所以全部划分到Stage 2
3.3 实现细节
handleJobSubmitted 会通过调用 org.apache.spark.scheduler.DAGScheduler#newResultStage 来创建finnalStage,即途中的Stage3
handleJobSubmitted
1
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
newResultStage
1
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
继续跟进,getParentStagesAndId
1
2
3
4
5
6
7
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
// 根据JobId获取parentStage
val parentStages = getParentStages(rdd, firstJobId)
// 获取当前id,并自增,所以父Stage 的id是最小
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
继续查看getParentStages
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 存储parent Stage
val parents = new HashSet[Stage]
// 存储已经访问的RDD
val visited = new HashSet[RDD[_]]
// 存储需要被处理的RDD
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
// 对已经便利过的RDD进行标记
visited += r
for (dep <- r.dependencies) {
// 匹配当前RDD的依赖,如果为ShuffleDependency,则生成新的stage,如果不是则继续压栈,那么也就是同一个stage
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
// 将RDD 进行压栈 然后进行处理
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}
在上述代码中,对指定的RDD的依赖进行了广度优先级便利,遇到窄依赖则归为统一stage,如果是宽依赖,则生成一个新的stage。显然,在这里只是对finalStage的依赖进行了便利,并没有对所有的RDD的依赖都进行便利。继续跟进 getShuffleMapStage
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
// 若是已经存在stage,则直接返回
case Some(stage) => stage
// 不存在则生成新的stage
case None =>
// 继续便利当前rdd 的依赖,并生成Stage
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// 为当前shuffle 生成新的stage
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
如果是第一次进行shuffleToMapStage,那么结果肯定是none,继续跟进getAncestorShuffleDependencies
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
// 保存所有的shuffle依赖,注意:与getParentStage不同的是,这里是保存所有的
val parents = new Stack[ShuffleDependency[_, _, _]]
// 记录已经被访问的RDD
val visited = new HashSet[RDD[_]]
// 建立Stack,保存等待被访问的RDD
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
// 打上标记
visited += r
// 便利当前RDD所有依赖
for (dep <- r.dependencies) {
dep match {
// 如果是shuffle依赖,并判断stage 并没有存在,则添加到parents中
case shufDep: ShuffleDependency[_, _, _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
// 注意:与getParentStage不同的是,即使是shuffleDependency的rdd也要继续遍历
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
这里似乎和getParentStages很像,但是这里确实便利了所有的祖先的依赖关系,而不是当前RDD的依赖关系
到此为止已经完成了所有shuffleStage的生成,来看看是如何生成的 newOrUsedShuffleStage
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
// 首先会判断当前stage是否被计算过,被计算过则重新计算一个新的stage
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// stage已经被计算过,从mapOutputTracker中获取计算结果
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
(0 until locs.length).foreach { i =>
if (locs(i) ne null) {
// 将计算结果拷贝到stage中
stage.addOutputLoc(i, locs(i))
}
}
} else {
// stage未被计算过,则向mapOutputTracker中对stage进行注册
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
到此位置,由finalRDD往前追溯递归生成Stage,最前面的ShuffleStage先生成,最终生成ResultStage,至此,DAGScheduler对Stage的划分已经完成。
3.3 任务的生成
先回到org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
1
2
3
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
...
submitStage(finalStage)
在完成stage划分后就开始提交stage了,submitStage
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 如果该stage没有等待其他parent stage返回,没有正在运行,且没有失败提示,阿么就提交他
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 确保所有的parent stage都已经完成,那么提交该stage所包含的task
submitMissingTasks(stage, jobId.get)
} else {
// 如果没有则递归提交他
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {// 无效stage,直接停掉
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
org.apache.spark.scheduler.DAGScheduler#submitMissingTasks会最终完成DAGScheduler所有的工作,即向TaskScheduler提交Task。提交的顺序图
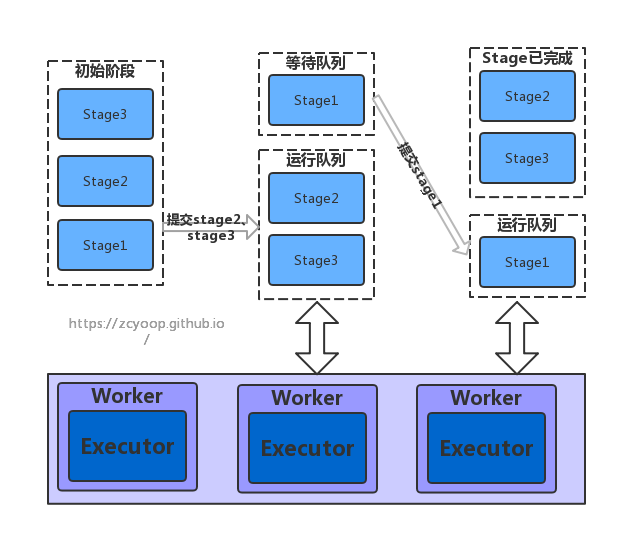
首先,取得需要计算的partition,对于最后的stage,它对应的是ResultTask,因此需要判断该Partition的ResultTask是否结束,如果结束则无需计算;对于其他的Stage,它们对应的Task都是ShuffleMapTask,因此只需要判断Stage是否有缓存结果即可
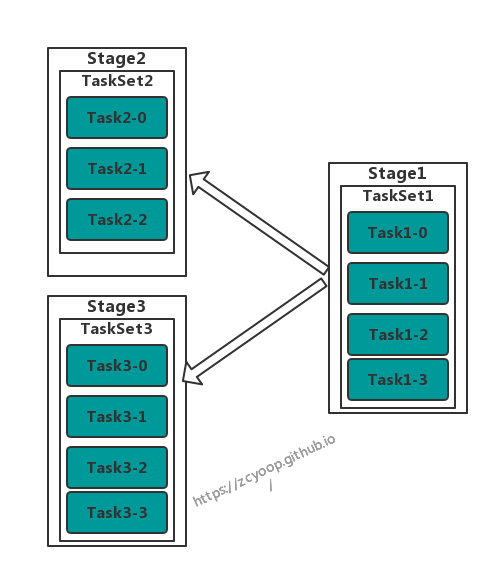
在判断出Partition需要计算后,就会为每个Partition生成Task,然后封装成TaskSet,最后提交给TaskScheduler,从逻辑上有上图变成了下图
TaskSet 保存了Stage的一组完全相同的Task,每个Task处理的逻辑完全相同,不同的是处理的数据,每个Task负责处理一个Partition,他们从数据源获取逻辑,然后按照拓扑顺序,顺序执行