
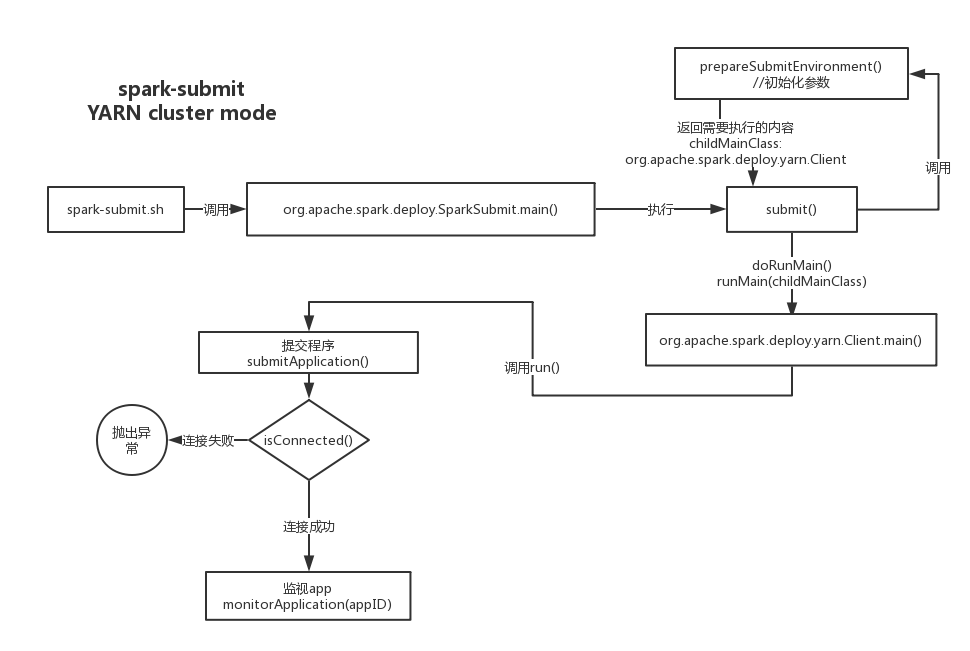
下图大致描述了整个过程
spark-submit
1
2
3
4
5
6
7
8
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
# 调用bin目录中的spark-class 参数为org.apache.spark.deploy.SparkSubmit
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
会先经历spark-class org.apache.spark.deploy.SparkSubmit处理,里面包括一些基本环境配置,然后运行
再看看 org.apache.spark.deploy.SparkSubmit的main函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
// 在这里进行操作的匹配,在这里我们肯定是进入submit()
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
submit()
1
2
3
4
5
private def submit(args: SparkSubmitArguments): Unit = {
//先是初始化环境,包括建立合适的环境变量,系统配置,应用参数
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
.....
}
prepareSubmitEnvironment(args)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/**
* Prepare the environment for submitting an application.
* This returns a 4-tuple:
* (1) the arguments for the child process,
* (2) a list of classpath entries for the child,
* (3) a map of system properties, and
* (4) the main class for the child
* Exposed for testing.
* 这些都是spark-submit 里面的一些配置,例如启动模式、环境变量。这个方法就是根据这些启动模式来做 * 出对应的处理,由于一般情况下会在yarn进行任务运行,所以这次运行的模式--master yarn --deploy- * mode cluster
*/
private[deploy] def prepareSubmitEnvironment(args: SparkSubmitArguments)
: (Seq[String], Seq[String], Map[String, String], String) = {
......
//前面都是一些判断,直接进入正题
if (isYarnCluster) {
//当为yarn 的cluster模式时 会调用org.apache.spark.deploy.yarn.Client类
childMainClass = "org.apache.spark.deploy.yarn.Client"
//是否使用Python
if (args.isPython) {
childArgs += ("--primary-py-file", args.primaryResource)
if (args.pyFiles != null) {
childArgs += ("--py-files", args.pyFiles)
}
childArgs += ("--class", "org.apache.spark.deploy.PythonRunner")
//或者使用R
} else if (args.isR) {
val mainFile = new Path(args.primaryResource).getName
childArgs += ("--primary-r-file", mainFile)
childArgs += ("--class", "org.apache.spark.deploy.RRunner")
} else {
//最后是默认情况,也就是我们这次任务执行的模式
if (args.primaryResource != SPARK_INTERNAL) {
childArgs += ("--jar", args.primaryResource)
}
childArgs += ("--class", args.mainClass)
}
if (args.childArgs != null) {
args.childArgs.foreach { arg => childArgs += ("--arg", arg) }
}
}
//最后通过筛选,返回这些参数
(childArgs, childClasspath, sysProps, childMainClass)
}
再回到submit(),会执行runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose),也就是传入我们刚刚返回的参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
//前面会根据传入的参数进行环境配置,参数导入以及日志的打印
......
try {
// 加载我们传入的类,也就是 org.apache.spark.deploy.yarn.Client
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
.......//捕捉异常信息,这里就忽略了
}
//获取传入类的main函数
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
......
try {
// 调用main函数
mainMethod.invoke(null, childArgs.toArray)
}
}
然后来看看org.apache.spark.deploy.yarn.Client.main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def main(argStrings: Array[String]) {
if (!sys.props.contains("SPARK_SUBMIT")) {
logWarning("WARNING: This client is deprecated and will be removed in a " +
"future version of Spark. Use ./bin/spark-submit with \"--master yarn\"")
}
// Set an env variable indicating we are running in YARN mode.
// Note that any env variable with the SPARK_ prefix gets propagated to all (remote) processes
System.setProperty("SPARK_YARN_MODE", "true")
val sparkConf = new SparkConf
val args = new ClientArguments(argStrings, sparkConf)
// to maintain backwards-compatibility
if (!Utils.isDynamicAllocationEnabled(sparkConf)) {
sparkConf.setIfMissing("spark.executor.instances", args.numExecutors.toString)
}
//在一顿初始化与判断后,初始化自己然后调用run()方法
new Client(args, sparkConf).run()
}
run()
1
2
3
4
5
6
7
8
9
10
def run(): Unit = {
//提交应用
this.appId = submitApplication()
if (!launcherBackend.isConnected() && fireAndForget) {
......
} else {
val (yarnApplicationState, finalApplicationStatus) = monitorApplication(appId)
......
}
}
submitApplication(),来看看提交应用里面做了什么
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
//launcherBackend在前面已经进行了初始化,launcherBackend是一个底层使用Socket用来传递信息的抽象类
launcherBackend.connect()
// Setup the credentials before doing anything else,
// so we have don't have issues at any point.
setupCredentials()
yarnClient.init(yarnConf)
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
// 通过yarn api 创建一个application
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
reportLauncherState(SparkAppHandle.State.SUBMITTED)
launcherBackend.setAppId(appId.toString())
// Verify whether the cluster has enough resources for our AM
// 检测集群是否有足够的资源可以调用
verifyClusterResources(newAppResponse)
// 初始化环境用于启动ApplicationManager
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
//最后提交应用,并返回appId
// Finally, submit and monitor the application
logInfo(s"Submitting application ${appId.getId} to ResourceManager")
yarnClient.submitApplication(appContext)
appId
} catch {
case e: Throwable =>
if (appId != null) {
cleanupStagingDir(appId)
}
throw e
}
}
提交完任务后在回到 run() ,通过代码可以看出,他会继续执行monitorApplication(appId),也就是监视任务的进行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
/**
* Report the state of an application until it has exited, either successfully or
* due to some failure, then return a pair of the yarn application state (FINISHED, FAILED,
* KILLED, or RUNNING) and the final application state (UNDEFINED, SUCCEEDED, FAILED,
* or KILLED).
*
* @param appId ID of the application to monitor.
* @param returnOnRunning Whether to also return the application state when it is RUNNING.
* @param logApplicationReport Whether to log details of the application report every iteration.
* @return A pair of the yarn application state and the final application state.
*/
def monitorApplication(
appId: ApplicationId,
returnOnRunning: Boolean = false,
logApplicationReport: Boolean = true): (YarnApplicationState, FinalApplicationStatus) = {
val interval = sparkConf.getLong("spark.yarn.report.interval", 1000)
var lastState: YarnApplicationState = null
while (true) {
Thread.sleep(interval)
val report: ApplicationReport =
try {
getApplicationReport(appId)
} catch {
case e: ApplicationNotFoundException =>
logError(s"Application $appId not found.")
return (YarnApplicationState.KILLED, FinalApplicationStatus.KILLED)
case NonFatal(e) =>
logError(s"Failed to contact YARN for application $appId.", e)
return (YarnApplicationState.FAILED, FinalApplicationStatus.FAILED)
}
val state = report.getYarnApplicationState
if (logApplicationReport) {
logInfo(s"Application report for $appId (state: $state)")
// If DEBUG is enabled, log report details every iteration
// Otherwise, log them every time the application changes state
if (log.isDebugEnabled) {
logDebug(formatReportDetails(report))
} else if (lastState != state) {
logInfo(formatReportDetails(report))
}
}
if (lastState != state) {
state match {
case YarnApplicationState.RUNNING =>
reportLauncherState(SparkAppHandle.State.RUNNING)
case YarnApplicationState.FINISHED =>
reportLauncherState(SparkAppHandle.State.FINISHED)
case YarnApplicationState.FAILED =>
reportLauncherState(SparkAppHandle.State.FAILED)
case YarnApplicationState.KILLED =>
reportLauncherState(SparkAppHandle.State.KILLED)
case _ =>
}
}
if (state == YarnApplicationState.FINISHED ||
state == YarnApplicationState.FAILED ||
state == YarnApplicationState.KILLED) {
cleanupStagingDir(appId)
return (state, report.getFinalApplicationStatus)
}
if (returnOnRunning && state == YarnApplicationState.RUNNING) {
return (state, report.getFinalApplicationStatus)
}
lastState = state
}