
Pandas导入
1
2
import pandas as pd
import numpy as np
创建DataFram
1
2
3
4
5
6
7
8
# 手动穿件数据集
df = pd.DataFrame([
[1001,'Mike',20],
[1002,'Bob',21],
[1003,'Alice',22],
])
# 从磁盘导入数据集
df = pd.read_excel('c:/Users/58212/Desktop/house_info_001.xlsx')
添加列名
1
df.columns=['编号','姓名','年龄']
读取前&后几行
1
2
df.head() # 默认读取前5行
df.tail() # 默认读取后5行
查看DataFrame描述信息
1
df.info

DataFrame 简单的统计量
1
df.describe().T

切片
1
2
3
4
5
6
# 获取单列
df['首付']
# 获取多列
df[['首付','建筑面积']]
# 获取指定几行指定几列
df.loc[1:7,['单价','建筑面积']]
筛选
1
2
3
4
5
df[df['首付']>250]
# 交集
df[(df['首付']>=150) & (df['朝向'] == '南北')].head()
# 并集
df[(df['首付']>=150) | (df['朝向'] == '南北')].head()
添加&删除&修改一列
1
2
3
4
5
6
7
8
9
# 新增列
df['测试']=True
df.head()
# 删除列
del df['测试']
# 新增并设置为空
df['测试列'] = np.nan
# 修改某个元素
df.loc[2,'住宅类别']='普通住宅'
检查缺失值
1
2
3
4
df['住宅类别'].isnull() # 输出‘住宅类别中’所有的值是否为空
df['住宅类别'].isnull().any() # 检查‘住宅类别中’是否有一列为空
df.isnull().any() # 检查所有列中是否含有控制
df.isnull().sum() # 对所有列中的空值进行计数
移除缺失值
1
2
3
4
5
6
7
8
9
# 函数作用:删除含有空值的行或列
# axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
# how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
# thresh:一行或一列中至少出现了thresh个才删除。
# subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
# inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改
df = df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
填补缺失行
1
2
3
4
5
6
7
8
# 函数作用:填充缺失值
#
# value:需要用什么值去填充缺失值
# axis:确定填充维度,从行开始或是从列开始
# method:ffill:用缺失值前面的一个值代替缺失值,如果axis =1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现
# limit:确定填充的个数,如果limit=2,则只填充两个缺失值。
df=df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
数据转换
1
2
3
4
5
6
7
8
9
10
11
# 修改数值
df['单价']=df['单价']*1000
# 移除单位
df['建筑面积']=df['建筑面积'].map(lambda x:x.split('平')[0])
df['建筑年代']=df['建筑年代'].map(lambda x:x.split('年')[0])
# 转换类型
df[['单价','建筑面积','首付']]=df[['单价','建筑面积','首付']].astype('float')
# 正则表达式
df[['室','厅','卫']]=df['户型'].str.extract('(\d)室(\d)厅(\d)卫') #将户型转成了3列
# 统计某列所有的值
df['住宅类别'].value_counts()
分类数据硬编码&One-Hot编码
1
2
3
4
5
6
7
8
9
10
# 分类数据硬编码,将某列的值转成对应数值,离散特征的取值有大小的意义
house_mapping={
'普通住宅':0,
'商住楼':1,
'公寓':2
}
df['住宅类别']=df['住宅类别'].map(house_mapping)
# One-Hot编码,离散特征的取值之间没有大小的意义
df=df.join(pd.get_dummies(df['楼层']))
探索性数据分析
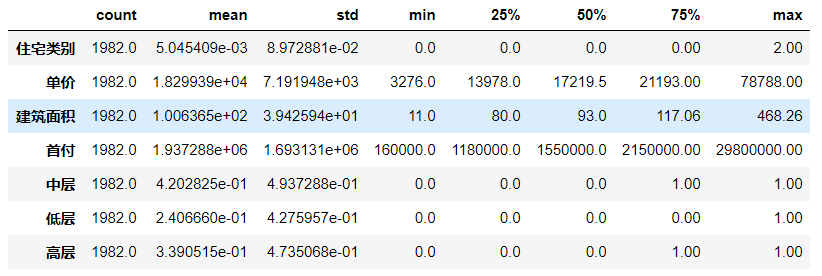
叙述性统计量
1
df.describe().T
便捷绘图
1
2
3
4
5
6
7
8
9
10
11
# 直方图,单价直方图
df['单价']=hist(bins=20) # 20个容器
plt.show()
# 箱线图,单价箱线图
p=df.boxplot(column='单价')
# 散点图
import matplotlib.pyplot as plt
plt.scatter(df['单价'],df['首付'])
plt.show()
# 皮尔逊相关系数,其其他参数的线性关系值
df.corr()