
1. Flink SQL的运行环境
在Flink1.15版本下,Flink对Scala依赖做了一定处理,参考Scala Free in One Fifteen。总而言之依赖不再受Scala版本的影响,所以对于Flink SQL的依赖也同样带来了一点变化,参考官网如下
| 您要使用的 API | 您需要添加的依赖项 |
|---|---|
| DataStream | flink-streaming-java |
| DataStream Scala 版 | flink-streaming-scala_2.12 |
| Table API | flink-table-api-java |
| Table API Scala 版 | flink-table-api-scala_2.12 |
| Table API + DataStream | flink-table-api-java-bridge |
| Table API + DataStream Scala 版 | flink-table-api-scala-bridge_2.12 |
Flink SQL运行环境如下:
1
2
3
4
5
6
7
8
// flinkVersion = 1.15.0
implementation "org.apache.flink:flink-table-api-java-bridge:${flinkVersion}"
// for table API runtime
implementation "org.apache.flink:flink-runtime:${flinkVersion}"
implementation "org.apache.flink:flink-table-runtime:${flinkVersion}"
implementation "org.apache.flink:flink-table-planner-loader:${flinkVersion}"
// execute in IDE
implementation "org.apache.flink:flink-clients:${flinkVersion}"
更多配置详细参考,项目配置
2. 程序骨架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 初始化环境配置
EnvironmentSettings settings = EnvironmentSettings.newInstance()
// 批处理模式
//.inBatchMode()
// 流处理模式
.inStreamingMode()
.build();
//根据环境配置创建Table Environment环境
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 使用Table API创建SourceTable临时表
tableEnv.createTemporaryTable("SourceTable", TableDescriptor.forConnector("datagen")
.schema(Schema.newBuilder()
.column("f0", DataTypes.STRING())
.build())
.option(DataGenConnectorOptions.ROWS_PER_SECOND, 2L)
.option("fields.f0.length", "1")
.build());
// 使用SQL创建SinkTable临时表
tableEnv.executeSql("CREATE TEMPORARY TABLE SinkTable(f0 String,num BIGINT) WITH ('connector' = 'print')");
// 执行SQL语句
Table table = tableEnv.sqlQuery("SELECT f0,COUNT(1) AS num FROM SourceTable GROUP BY f0");
// 将执行结果输出
TablePipeline insertPipeline = table.insertInto("SinkTable");
insertPipeline.execute();
// 等同于上面两句
table.executeInsert("SinkTable");
从整个程序看来,一个Table API&SQL程序主要包含以下几个步骤:
- 创建表环境(TableEnvironment)
- 获取表信息
- 使用
Table API或SQL对表数据进行操作 - 将结果输出到外部系统(调用execute(),调用这一步也可被整合到一起)
3. 创建TableEnvironment
TableEnvironment是Table API & SQL编程中最基础的类,也是整个程序的入口,它包含了程序的核心上下文信息,除此以外TableEnvironment核心功能还包括:
- 向
Catelog中注册Table或者获取Table,即表管理 Catelog管理- 注册用户自定义函数
- 加载可插拔
Module - 执行SQL脚本
- DataStream 和 Table(Table\SQL API 的查询结果)之间进⾏转换
创建TableEnvironment具体代码
- 通过环境配置之间进行创建 ```java import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings .newInstance() .inStreamingMode() //.inBatchMode() .build();
TableEnvironment tEnv = TableEnvironment.create(settings);
1
2
3
4
5
6
7
8
9
2. 通过`StreamExecutionEnvironment`转换过来
```java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
4. 创建Table
⼀个表的全名(标识)会由三个部分组成: Catalog名称.数据库名称.表名称 ,如果 Catalog名称或者数据库名称没有指明,就会使⽤默认值 default 例如,下⾯这个SQL创建的Table的全名为default.default.table1
1
tableEnv.executeSql("CREATE TEMPORARY TABLE table1 ... WITH ( 'connector' = ... )");
表根据来源又分为视图(虚拟表)和普通表(外部表)
- 视图 VIEW (virtual table):从已经存在的表中创建,视图⼀般是⼀个 SQL 逻辑的查询结果
1 2 3 4 5
TableEnvironment tableEnv = ...; // 通过对表X进行一定的查询 Table projTable = tableEnv.from("X").select(...); // 将查询结果注册成临时视图projectedTable1 tableEnv.createTemporaryView("projectedTable1", projTable);
- 外部表 Connector Tables:描述的是外部数据,例如⽂件(HDFS)、消息队列(Kafka)等。具体外部表创建可参考Table & SQL Connectors
1 2 3 4 5 6 7 8 9 10 11 12 13
// 可以通过Table API继续创建,也可以通过SQL进行创建 // Table API,使用TableDescriptor对表信息进行描述 final TableDescriptor sourceDescriptor = TableDescriptor.forConnector("datagen") .schema(Schema.newBuilder() .column("f0", DataTypes.STRING()) .build()) .option(DataGenOptions.ROWS_PER_SECOND, 100) .build(); // 将表信息注册成表,以下为临时外部表和永久外部表 tableEnv.createTable("SourceTableA", sourceDescriptor); tableEnv.createTemporaryTable("SourceTableB", sourceDescriptor); // 通过SQL对表进行创建 tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable (...) WITH (...)");
临时表&永久表 表(视图、外部表)可以是临时的,并与单个 Flink session(可以理解为 Flink 任务运⾏⼀次就是⼀个 session) 的⽣命周期绑定,也可以是永久的,并且在所有的 Flink session 都⽣效
- 临时表:通常保存于内存中并且仅在创建它们的 Flink session(可以理解为⼀次 Flink 任务的运⾏)持续期间存在。这些表对于其它 session(即其他Flink任务或⾮此次运⾏的 Flink 任务)是不可⻅的。因为 这个表的元数据没有被持久化
- 永久表:需要外部 Catalog来持久化表的元数据。⼀旦永久表被创建,它将对任何连接到这个Catalog的 Flink session 可⻅且持续存在,直⾄从 Catalog 中被明确删除
- 如果临时表和永久表使⽤了相同的名称(
Catalog名.数据库名.表名)。那么在这个 Flink session 中,你的任务访问到这个表时,访问到的永远是临时表(即相同名称的表,临时表会屏蔽永久表)
5.在Table上进行查询
5.1 Table API
基于Table,我们可以调用Table API或者SQL来查询其中的数据。Table API和编程语言结合更紧密,我们可以在Table类上使用链式调用,调用Table类中的各种方法,执行各类关系型操作。如下
1
2
3
4
5
6
7
8
//获取Table Environment环境
TableEnvironment tableEnv =...
//创建表(也可以忽略此步直接获取表信息)
//对表进行查询
Table table = tableEnv
.from("SourceTable")
.groupBy($("f0"))
.select($("f0"), $("f0").count().as("num"));
更多Table API,参考Table API
5.2 SQL
我们也可以直接在Table执行SQL语句。SQL标准中定义了一系列语法和关键字,开发者可以基于SQL标准来编写SQL语句。与Table API中函数调用的方式不同,SQL语句是纯文本形式的。Flink SQL基于Apache Calcite(以下简称Calcite),将SQL语句转换为Flink可执行程序。Calcite支持SQL标准,因此Flink SQL也支持SQL标准。
1
2
3
4
5
//获取Table Environment环境
TableEnvironment tableEnv =...
//创建表(也可以忽略此步直接获取表信息)
//对表进行查询
Table table = tableEnv.sqlQuery("SELECT f0,COUNT(1) AS num FROM SourceTable GROUP BY f0");
6. 结果输出
我们可以将查询结果通过TableSink输出到外部系统。TableSink和之前提到的Sink很像,它是一个数据输出的统一接口,可以将数据以CSV、Parquet、Avro等格式序列化,并将数据发送到关系型数据库、KV数据库、消息队列或文件系统上。TableSink与Catalog、Schema等概念紧密相关。
1
2
3
4
5
6
7
8
9
10
11
12
//获取Table Environment环境
TableEnvironment tableEnv =...
//创建表(也可以忽略此步直接获取表信息)
//对表进行查询
Table table = ...
// 创建用于输出的结果表
tableEnv.connect(new FileSystem().path("..."))
.withFormat(new Csv().fieldDelimiter('|'))
.withSchema(schema)
.createTemporaryTable("CsvSinkTable");
// 结果输出
table.insertInto("CsvSinkTable");
7. 执行作业
以上部分是一个Table API & SQL作业的核心代码编写阶段,但千万不要忘记调用execute方法来执行这个作业,以下为作业执行的大致流程 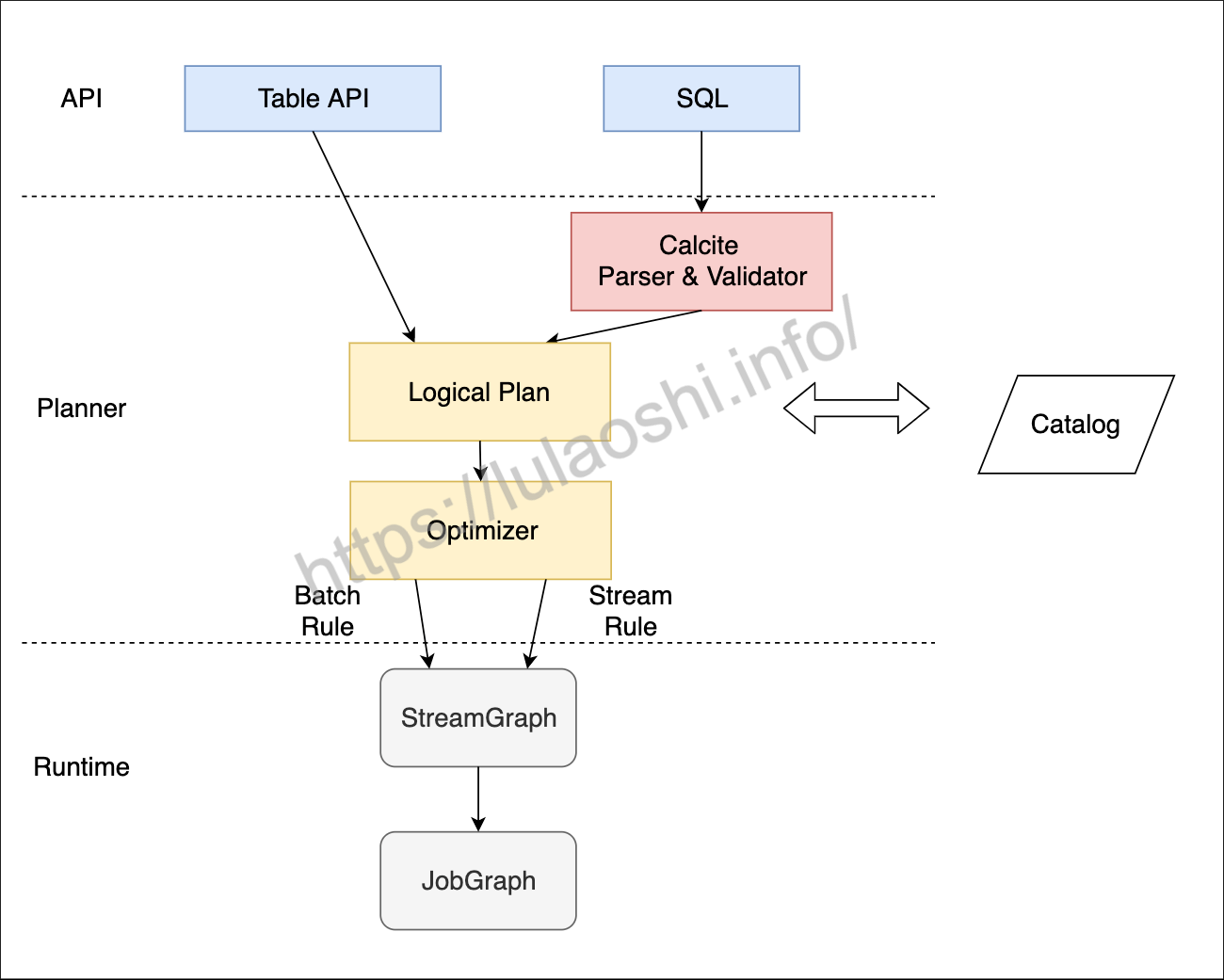 Table API & SQL从调用到执行的大致流程。一个Table API或者SQL调用经过Planner最终转化为一个
Table API & SQL从调用到执行的大致流程。一个Table API或者SQL调用经过Planner最终转化为一个JobGraph,Planner在中间起到一个转换和优化的作用。对于流作业和批作业,Blink Planner分别有相应的优化规则 也可以使用TableEnvironment.explain(table)来将查询转化为物理执行计划。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
System.out.println(table.explain());
== Abstract Syntax Tree ==
LogicalProject(f0=[$0], num=[$1])
+- LogicalAggregate(group=[{0}], EXPR$0=[COUNT($0)])
+- LogicalTableScan(table=[[default_catalog, default_database, SourceTable]])
== Optimized Physical Plan ==
GroupAggregate(groupBy=[f0], select=[f0, COUNT(f0) AS EXPR$0])
+- Exchange(distribution=[hash[f0]])
+- TableSourceScan(table=[[default_catalog, default_database, SourceTable]], fields=[f0])
== Optimized Execution Plan ==
GroupAggregate(groupBy=[f0], select=[f0, COUNT(f0) AS EXPR$0])
+- Exchange(distribution=[hash[f0]])
+- TableSourceScan(table=[[default_catalog, default_database, SourceTable]], fields=[f0])
可以得到相应的语法树(未优化的逻辑执行计划)、优化后的逻辑执行计划以及最终的物理执行计划 以上就是Flink SQL的基本使用