
1. Kafka副本简介
在 Kafka 0.8.0 之前,Kafka 是没有副本的概念的,那时候人们只会用 Kafka 存储一些不重要的数据,因为没有副本,数据很可能会丢失。但是随着业务的发展,支持副本的功能越来越强烈,所以为了保证数据的可靠性,Kafka 从 0.8.0 版本开始引入了分区副本。也就是说每个分区可以人为的配置几个副本(比如创建主题的时候指定 replication-factor,也可以在 Broker 级别进行配置 default.replication.factor),一般会设置为3。
Kafka中的副本同一分区的不同副本保存的消息是相同的(在同一时刻,副本之间并非完全一样,后面的一些内容就是为了解决这个问题),副本之间是“一主多从”的关系,其中Leader副本负责处理读写请求,Follower副本只负责与Leader进行消息同步。副本处于不同的Broker中,当Leader副本出现故障时,会从Follower副本中重新选举新的Leader副本对外提供服务。Kafka通过多副本机制实现了故障自动转移
1.1 副本机制中的一些概念
如图所示,Kafka中有4个Broker,其中某个主题有3个分区,且副本因子也为3,如此每个分区便有1个Leader和2个Follower。其中生产者只与Leader进行交互,而Follower只负责消息同步,但是当有很多Follower时,Follower副本中的消息就有可能相对Leader有一定滞后
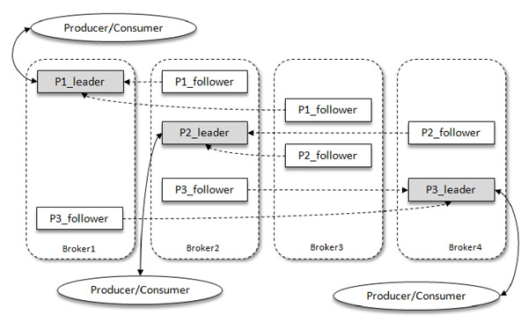
分区中所有的副本(Leader和Followers)统称AR(Assigned Replicas)。所有与Leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合的一个子集。所有消息发送到Leader,然后Follower副本才能从Leader副本中进行消息同步,而同步期间Follower会有一定程度消息滞后,这个“一定程度消息滞”是指可容忍的滞后范围,这个可以通过参数进行配置。与Leader同步之后过多的Follower组成OSR(Out-of-Sync Replicas),所以AR = ISR+OSR,不过正常情况下AR = ISR。 ISR与HW和LEO也有紧密联系。HW(High Watermark,高水位),它标识了一个特定的消息偏移量,消费者只能拉渠道这个offset之前的消息。
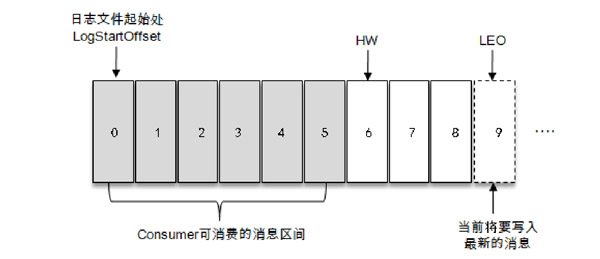
如下图所示,消费者只能拉取offset在0到5之间的数据,而offset为6的消息对消费者来说是不可见的。LEO(Log End Offset),它标识当前日志文件下一条待写入消息的offset,即下图offset为9的位置,LEO的大小相当于当前日志分区中最后一条消息的offset+1.
2. ISR集合的伸缩
2.1 副本失效
正常情况下,分区的所有副本都处于ISR集合当中,但是Follower副本难免会有一些异常情况的发生,也就是简介中描述的“超过一定滞后范围”,或者是机器出现异常,从而某些副本会被剥离出ISR集合当中
这些信息可以通过kafka-topics.sh脚本中的under-replicated-partitions参数来显示主题中所包含失效副本的信息
如果是机器发生故障, 那么肯定会直接被归为异常副本,所以这里主要讨论的是机器由于性能或其他原因导致的同步失效状态。
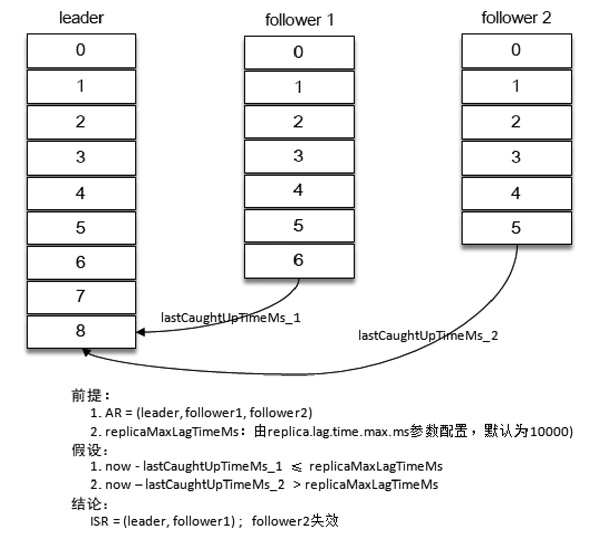
Kafka从0.9x版本开始,就通过唯一的broker端参数replica.lag.time.max.ms来进行抉择,当ISR集合中的一个Follwer副本滞后Leaders的时间超过此参数指定的值则判定为同步失败,需要将该Follower剔除出ISR集合,如下图所示
ps:一般这两种情况会导致副本失效
- follower副本进程卡住,在一段时间内根本没有向leader副本发出同步请求,例如频繁的Full GC
- follower副本进程同步过慢,在一段时间内都无法追赶上leader副本,比如I/O开销过大
2.2 副本恢复
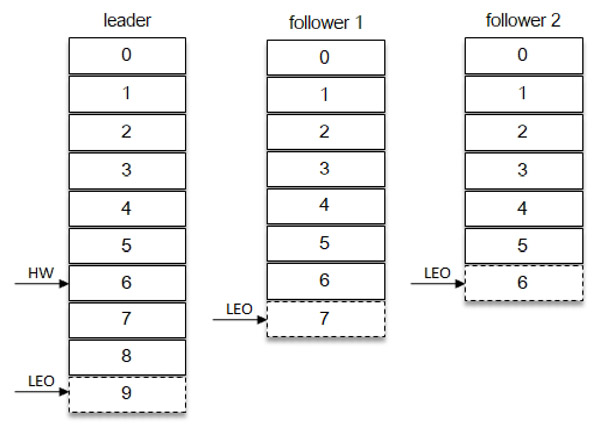
副本恢复的条件很简单,随着Follower副本不断与Leader进行消息同步,Follower副本的LEO也会逐渐后移,最终追赶上Follower副本就有资格进入ISR集合。追赶Leader的判断标准是此副本的LEO是否小于Leader副本的HW,而不是Leader的LEO 如下图所示,Leader副本LEO为9,Follower1的LEO为7,而Follower的LEO为6,如果判定这3个副本都属于ISR集合中,那么这个分区的HW则为6;如果Follower2被判断为失效副本剥离出ISR集合,那么此时HW为7
2.3 LEO&HW
上文介绍了副本的恢复是通过Follower副本的LEO和Leader的HW来进行判断,下面介绍LEO与HW之间的变化关系 如下图所示,假如生产者一直往Leader(带阴影的方框)写入消息,其中某一时刻,Leader的LEO为5,其他所有Followers副本(不带阴影)HW都是0
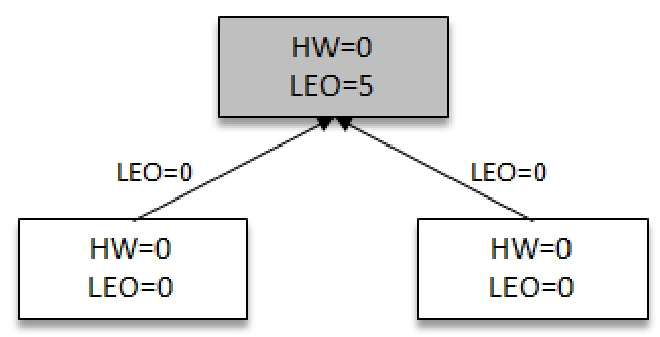
之后Followers向Leader拉去消息,在拉去的请求中会带有自身的LEO信息。Leader返回给Followers副本相信的消息,并带有Leader自身的HW信息
此时两个Follower各自拉取到了消息,并更新各自的LEO分别为3,4。与此同时,Follower还会更新自己的HW,更新HW的算法是比较当前LEO和Leader传送过来的HW值,去较小值为自己的HW值。两个Followers副本HW值为0(min(0,0)=0)
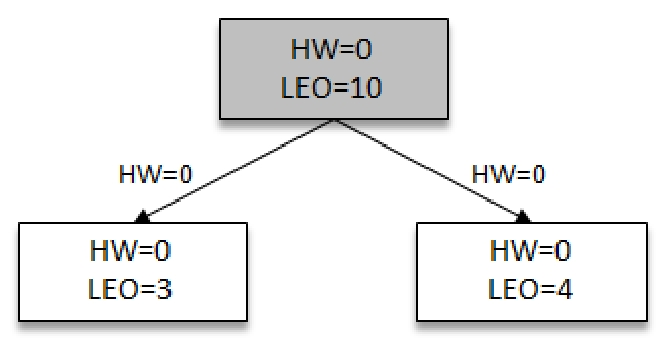
此时Leader再次受到Followers的请求信息,并带有自身的LEO信息(3,4),Leader通过自身的LEO和Follower的LEO信息进行比对,取出最小值3最为最新的HW。然后将最新的HW信息连同消息一起返回给Followers
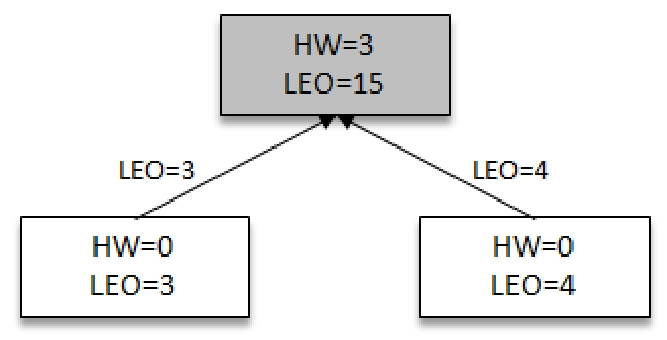
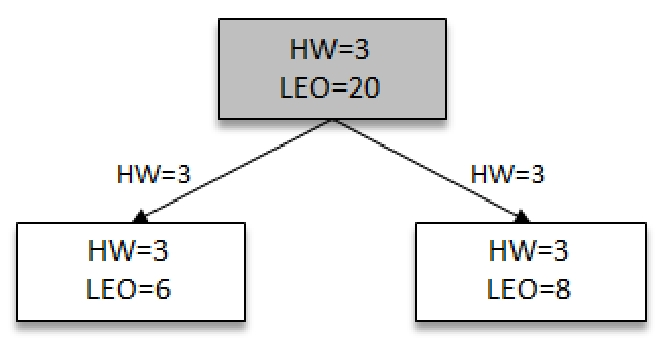
然后Followers再次拉去到Leader的HW信息和数据信息,分别跟新自己的LEO和HW信息3
3. Leader Epoch的介入
在Kafka 0.11之前,Kafka都是基于HW的同步机制来进行的,但是会出现L数据丢失或是Leader副本和Follower副本数据不一致的问题。
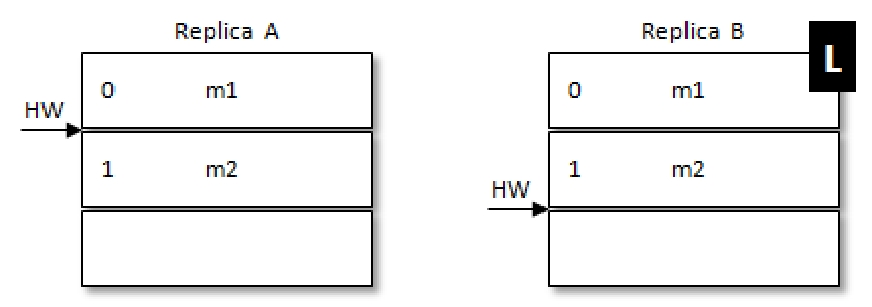
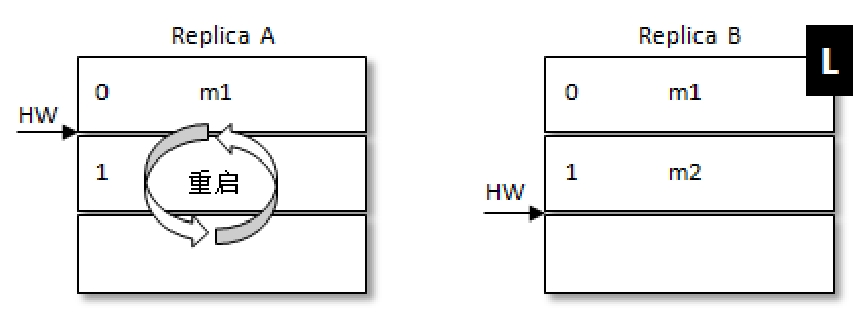
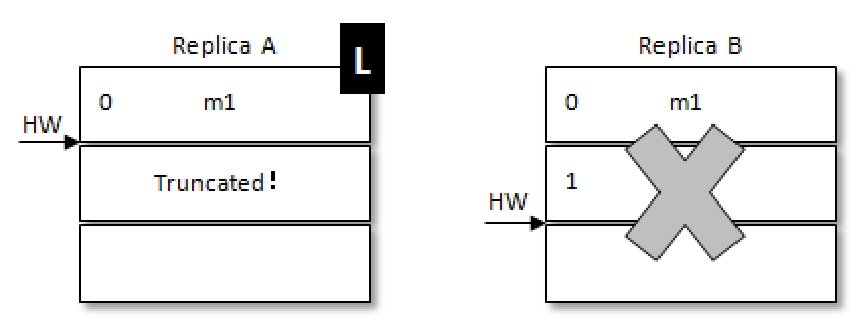
例如,带L的是Leader。此时处于RB刚刚更新完自己的HW,但是RA还未获取到最新的HW,RA这个时候机器重启,此时RA中大于HW的数据就会被截断,在RA重启后RB接着重启,RA就会被选作Leader这样就会导致m2这条消息丢失
想要解决这样的问题,可以等待所有Follower副本更新完HW之后再更新Leader的HW,但这样会增加多一轮FetchRequest/FetchResponse延迟,所以不是太妥当。Kafka的方式是引入Leader Epoch(简称LE),LE会在每次Leader发生变化后+1,每条数据都带有LE信息,那么再看下上述问题在引入LE后的情况
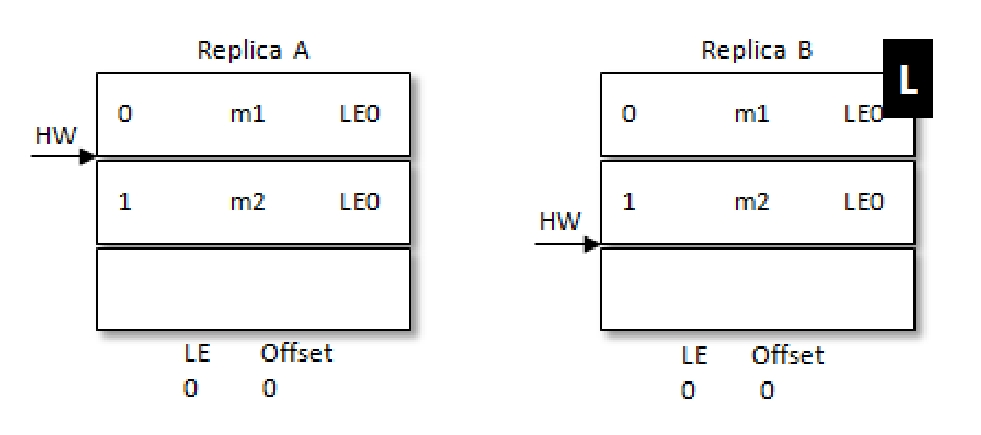
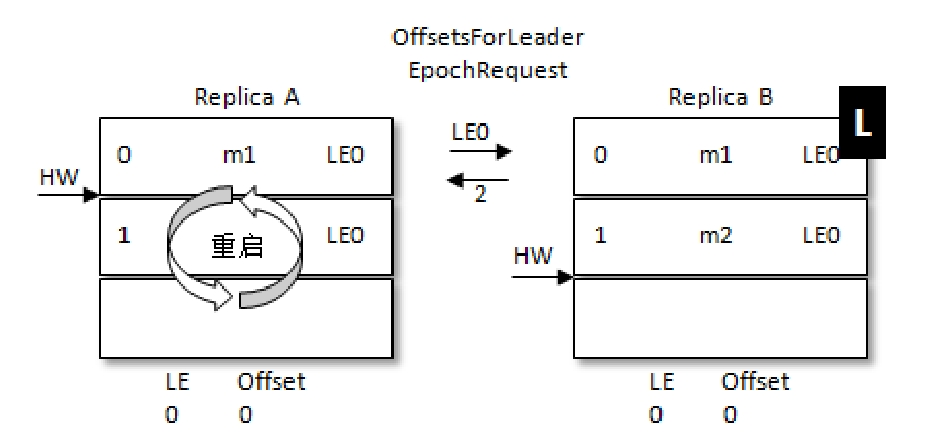
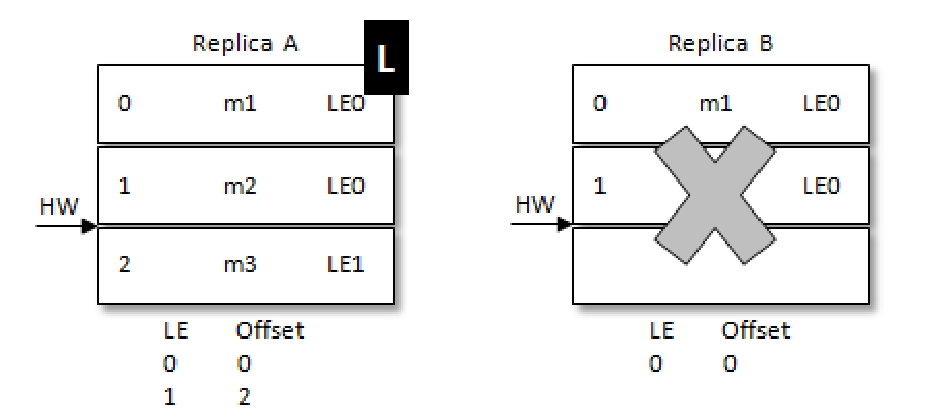
同样是RA先重启,但是重启后不是直接截断大于HW的数据,而是会像当前的Leader发送自己的当前的LE信息(假设LE_A),如果此时LE_A和B中的不同,那么B此时会查找LeaderEpoch为LE_A+1对应的StartOffset并返回给A,也就是LE_A对应的LEO。但是在上面的例子中,会发现A收到的LEO相同,则就不需要截断HW后面的数据。
之后和上面的例子一样,RB宕机,A成为Leader,LE从0变为1,对应的m2消息也得到了保留。
参考
- 《深入理解Kafka:核心设计与实践原理》